Head-of-Line Blocking
Head-of-Line (HoL) blocking refers to a situation where:
- Guaranteed messages are being sent over DMR links or VPN Bridge links between event brokers, and
- one or more Guaranteed endpoints is full
- some Guaranteed messages can't be delivered because they are stuck behind messages that are destined for one of the full endpoints
When an endpoint is full, and a new message is published to that endpoint, the event broker has only two choices available to it. The event broker can either discard the message, or it can refuse to accept the new message from the publisher. The default action of the event broker is to push back on the publishers of messages to that endpoint, by sending negative-acknowledgements (NACKs) to the publisher. This default behavior ensures that the event mesh never loses a published message.
This mechanism is very effective when the publisher and consumer of the message are on the same event broker. In this case, the only publishers affected are the ones trying to send messages to that full endpoint. The problem arises when the publisher and the consumer are on different event brokers, and the messages must be sent over an inter-broker link (either a DMR link or a VPN bridge). This situation is illustrated in the following diagram:
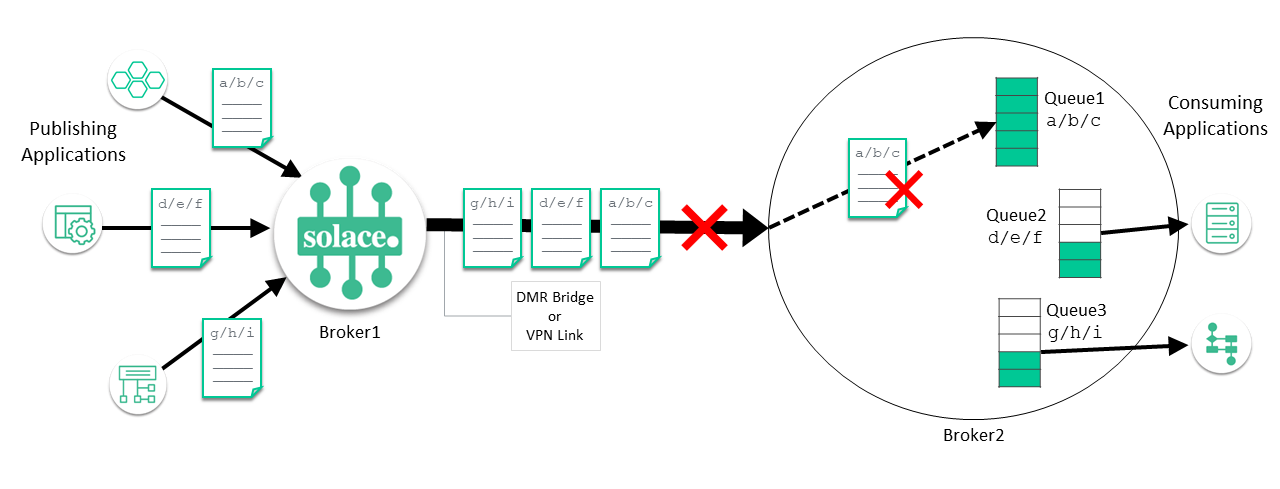
In the diagram above, Queue 1 (subscribed to topic a/b/c) is full because there is no connected client to consume the messages in the queue. Because the messages are originating on another event broker, Event Broker 2 can't send a NACK to the event broker that published the message because Event Broker 1, has already sent an ACK to the publishing application. As a result, Event Broker 2 simply discards the message. Event Broker 1 times out waiting for an ACK from Event Broker 2, and after the timeout has elapsed, it redelivers the message.
As a result, messages published to topic d/e/f on Queue 2, and topic g/h/i on Queue 3 can't be delivered, because they're stuck behind, or head-of-line blocked, by the messages on the inter-broker link that are being sent to topic a/b/c. That one full queue prevents all other Guaranteed messages destined for that Message VPN from being delivered over the inter-broker link.
How to Prevent Head-of-Line Blocking
To prevent HoL blocking, you can monitor your event brokers to detect the conditions where it may occur, and also choose configuration settings that reduce its likelihood.
Monitor for Guaranteed Endpoints That Aren't Being Serviced
The most important tool in preventing head of line blocking is monitoring the alert events for queue and topic endpoints. If an application isn't consuming messages from an endpoint (or isn't consuming them fast enough), the endpoint fills up and the Message VPN gets HoL blocked. Solace has chosen the default values for endpoint depths and alerting thresholds with the goal of providing sufficient time for you to fix this issue. How much time you have to react depends very much on the size of messages being written to the endpoint, and the rate at which messages are being delivered to the endpoint.
The following table shows how much time you have to react to alerts, assuming the default depth and alerting thresholds that the event broker assigns to endpoints when they are created (you can, of course, tune these values to better suit your needs). The table also assumes a 1 KB message size, a default queue size, and a default alert threshold.
| Inbound Rate to Guaranteed Endpoint | Time to React (From Alert to Endpoint Full) |
|---|---|
| 1K msg/sec | 62.5 minutes |
| 30K msg/sec | 2.08 minutes |
When the event broker alerts an administrator that an endpoint is getting full, the administrator should:
- Reach out to the "owner" of the endpoint, and work with them to get the consumer application back on-line and consuming from the endpoint
- If the queue is a non-exclusive queue, but the offered traffic rate is so high that the consuming applications can't keep up, add more consumer applications to the queue to further divide the workload
- If the endpoint's consumer can't be restored, shut down ingress on the endpoint. Note that this solution is only effective when the endpoint has not been configured as
reject-msg-to-sender-on-discard including-when-shutdown.This action causes messages destined for the endpoint to be discarded.
Ensure Message Spools Are Properly Sized
It's also very important that you have a large message spool configured on the event broker. It must be large enough that one full endpoint can't use up the entire message spool allocated to either the Message VPN or the event broker. Solace recommends that the max-spool-usage property for each message VPN be set to at least 10 GB, and preferably 25 GB or more. We also recommend that max-spool-usage for the entire event broker be set to the sum of max-spool-usage for each of the Message VPNs (this is an especially important consideration for the software event broker, where the default max-spool-usage for the event broker is a very small value to allow it to run in a small footprint on designers' laptop and desktop computers).
For details about the default values for max-spool-usage, see Maximum Spool Usage.
Choose "Discard" Rather Than "Block Publisher" Actions on Your Endpoints
The Solace Event Broker defaults to endpoint options that err on the side of never losing a message.
If your application messages have a limited lifetime, then Solace recommends enabling time-to-live (TTL) on the endpoints, so that old messages that haven't been consumed from the endpoint are automatically removed from that endpoint.
If you have the endpoint configured to send messages to a dead-message-queue (DMQ) on TTL expiry, make sure that you have an active consumer reading messages from the DMQ. If the event broker can't move a message to a DMQ, the event broker discards the message.
You can also configure the endpoints to discard messages destined for full endpoints, rather than rejecting the message to the publisher. This ensures that inter-broker links never get HoL blocked when the endpoint is full. Instead, new messages destined for that endpoint are discarded.
Use Replay to Recover Discarded Messages
If the Message VPN containing the endpoints causing HoL blocking has message replay enabled, this may make it more viable for you to choose "discard" rather than "block publisher" actions on your endpoints. After the consumer is back online, you can use replay to deliver the discarded messages to the consumer. Message replay can be initiated by the consuming application or the event broker administrator. In this scenario, it's likely that the event broker administrator will need to initiate the replay towards the endpoint that experienced the message discards.
Relying on replay to recover discarded messages assumes that the consumer can been brought back online within a reasonable period of time, before any discarded messages have been removed from the replay log. The replay log makes use of the same disk storage as the message spool, so it doesn't have infinite capacity.