Solace Cache and Event Broker Redundancy
Solace Cache is designed to provide redundancy through instantiating multiple Solace Cache Instances for each cluster. Any number of Solace Cache Instances can be provisioned across multiple servers and locations to Solace Cache to protect from a single network event affecting the entire cluster. Solace recommends that for each cluster, you connect at least one Solace Cache Instance to each active event broker in the event mesh.
Solace Cache is a Direct messaging service. Unless you need Guaranteed messaging for other applications that use the same event brokers that Solace Cache connects to, there is no advantage to deploying the event brokers as high availability (HA) pairs. However, if you also need to support Guaranteed messaging with your event brokers, then you can deploy your event brokers in HA pairs. In that case, you need to choose between the active/standby and active/active redundancy models.
Active/active redundancy applies only to Direct messaging on the event broker. Guaranteed messaging is always active/standby regardless of the redundancy model chosen.
HA pairing of event brokers ensures that there is no loss of Guaranteed messages in the event of a broker failure. Direct messaging and Solace Cache cannot offer the same delivery guarantees, even in an HA pair. So while HA pairing of event brokers ensures rapid restoration of service to publishers and consumers following an event broker failure, any messages published to an event broker at the moment of its failure may not be delivered to some or all of the other event brokers and Solace Cache Instances in an event mesh. Furthermore, depending upon the redundancy model chosen, there may be additional messages published to the mesh that are not delivered to one or more Solace Cache Instances in the mesh while the failover is happening.
Solace Cache Instances communicate with the Cache Manager whenever they establish a connection to an event broker. Following the initial communication, Solace Cache Instances can tolerate loss of communication with the Cache Manager and are capable of continuing service to an event mesh as long as they remain connected. Assuming at least one Solace Cache Instance per event broker, a loss of Cache Manager connectivity does not result in an interruption or loss of caching services in the event mesh.
Generally, only one event broker must be designated as a Cache Manager. However, for redundancy, you can designate an HA pair for cache management to follow activity, as it is redundancy aware. This applies to all redundancy models.
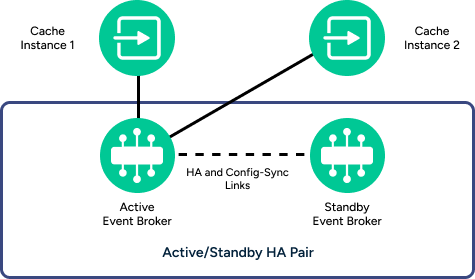
The active/standby model is the only supported solution if you are managing a distributed cache on an HA pair of software event brokers or if you are using Dynamic Message Routing (DMR) to interconnect the event brokers into an event mesh.
This approach provides administrative advantages in that if the failing event broker was providing Cache Manager services, the Cache Manager on the backup event broker can accept registration from Solace Cache Instances immediately following a failover.
Following a failover, there is a brief period of time before the newly-active event broker has connectivity to at least one Solace Cache Instance in the event mesh. During that period, messages published to the newly-active event broker are not cached anywhere in the mesh, and cache requests from clients connecting to that event broker do not receive cache responses. This means applications must be able to tolerate possible loss of cached messages and requests during and after a service affecting event on the active event broker.
Solace Cache Instances are able to immediately re-register with the active Cache Manager without administrative intervention because its availability follows the active event broker in an HA pair for appliance event brokers (if stop-on-lost-message is disabled). For more information, see Configuring Stop On Lost Message Behavior.
For software event brokers, Solace Cache Instances can also immediately re-register with the Cache Manager of the active event broker (without administrative intervention) if the use of hostlists (the SESSION_HOST parameter) for each of the cache instances contain the IP address or hostname of both the primary and backup event brokers in an HA redundancy group. The re-registration occurs if the configuration is adhered to as described in the Active/Standby Redundancy Model section in Configuration Summary.
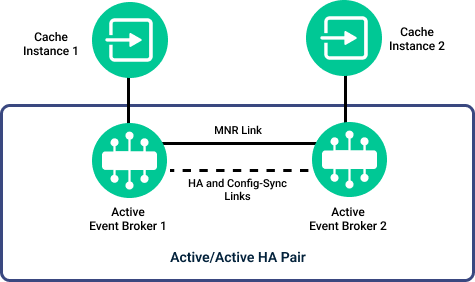
The active/active redundancy model is the preferred solution when using Solace Appliance Event Brokers but is not supported by software event brokers, and is not supported when using Dynamic Message Routing (DMR) to interconnect the event brokers in an event mesh. While this approach is still subject to potential message loss at the moment of event broker failure, it does have the advantage of having a subset of the Solace Cache Instances maintaining a connection to an event broker at all times. The HA mate event broker and its associated Solace Instances are already online and able to immediately provide caching services to the clients that were previously connected to the failed event broker.
Solace Instances are able to immediately re-register with the active Cache Manager (without administrative intervention) because the Cache Manager availability follows the active event broker in an HA pair (presuming stop-on-lost-message is disabled and the required configuration is adhered to). See Configuring Stop On Lost Message Behavior) and Active/Active Redundancy Model configuration in Configuration Summary.
Configuration Summary
Active/Standby Redundancy Model (Software Event Brokers or Appliance event brokers)
- Disable
auto-revertfor Appliance event brokers. For more information, see Configuring Redundancy Parameters. - Appliance event brokers must have their redundancy role configured as
primaryorbackup. For more information, see Assigning the Active/Standby Role. - Use Config-Sync to ensure that Solace Cache and client configurations are consistent on both the primary and backup event brokers.
- Both Solace Cache Instances must be configured as part of the same cache cluster and belong to a single Distributed Cache.
- When connection is to a software event broker, each Solace Cache Instance
SESSION_HOSTconfiguration property must specify the IP or hostname of both the active and backup event broker (comma delimited).
In the event of a failover, no administrative action is required if stop-on-lost-message is disabled on all Solace Cache Instances. If that is not the case, an administrator must restart each of the affected cache instances.
Active/Active Redundancy Model (Appliance event brokers with MNR or VPN-Bridged Event Mesh)
- Configure the event brokers as a non-revertive redundant pair.
- Use Config-Sync to ensure Solace Cache and client configurations are consistent on both event brokers.
- An MNR neighbor connection must be configured between the event brokers in the redundant pair. However, because this is an in-data-center LAN connection, assign it a very low cost (Solace recommends assigning a link cost of 1).
- Export subscriptions must be enabled on the Message VPN hosting the Distributed Cache.
- Both Solace Cache Instances shown must be configured as part of the same cache cluster and belong to a single Distributed Cache.
- Each Solace Cache Instance
SESSION_HOSTconfiguration property must specify the IP of both pairs in the event broker (comma delimited), with each instance specifying a different event broker in the pair as its first choice.
What to Do After Redundancy Failovers
If one event broker in the HA pair fails or is taken offline, the remaining event broker takes activity and provides service for the affected publishers and subscribers. Those clients reconnect and have access to Solace Cache and all cached data that was published prior to the failover through the Solace Cache Instances that retained connectivity with the event mesh. Any cache instances connected directly to the failed or offline event broker must re-establish connection to the event mesh.
Any published data that was in the process of delivery at the time of the failure may be lost and may not be available in the Solace Cache Instances on the backup event broker.
If the Solace Cache Instances that lost connectivity due to the failure are configured with stop-on-lost-message disabled, they connect to the alternative event broker and immediately resume service without administrator intervention. This results in each of those cache instances reporting a Lost Message state. For more information, including instructions on how to clear this state, see Lost Message State.
Solace Cache Instances that lost connectivity and are configured with stop-on-lost-message enabled require intervention to restore cache function. Those instances must be restarted.