High Availability for Software Event Brokers
You can deploy Solace Software Event Brokers in high-availability (HA) redundancy groups for fault tolerance. An HA redundancy group is made up of three event broker instances: two acting as active-standby messaging nodes and a third acting as a monitoring node. An HA redundancy group provides 1:1 event broker sparing to increase overall service availability. If one of the event brokers fails or is taken out of service, the other event broker automatically takes over and provides service to the clients that were previously served by the now-out-of-service event broker.
Software Event Broker HA Redundancy Model
Solace Software Event Brokers support an active/standby redundancy model. With this model, a primary messaging node provides messaging services to clients, while a backup event broker waits in standby mode—it only provides service should the primary event broker fail. A third event broker acts as a monitoring node, to act as a tie-breaker and prevent split-brain scenarios that would otherwise cause both the primary and backup messaging nodes to become active simultaneously.
The software event broker HA redundancy model supports both Direct and Guaranteed messaging clients.
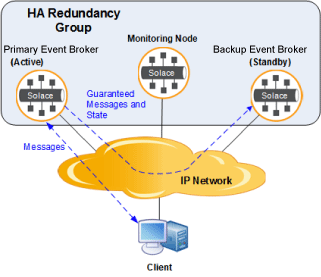
In the active/standby model:
- All clients connect to the active event broker in the redundancy group (typically the primary messaging node).
- The other event broker (typically the backup messaging node) acts only as a standby. While one primary event broker is active, clients cannot connect to the standby event broker, and no messaging traffic can flow through the standby.
- The active event broker uses the IP network to automatically propagate all Guaranteed messages and Guaranteed messaging state to the standby event broker.
- If the primary messaging node fails for any reason, the backup messaging node will become active and provide messaging services to the clients.
- When the primary messaging node comes back online, the backup messaging node continues to provide service to the clients, while it automatically resynchronizes its Guaranteed messages and the Guaranteed messaging state with the primary messaging node. Once resynchronized, the backup messaging node can continue to provide service to the clients (the default behavior for the software event broker).
Synchronizing Software Event Broker Configurations
The primary and backup messaging nodes in a software event broker HA redundancy group must have the same system and Message VPN level configurations, and this configuration must remain in sync while the event brokers are running. The Config-Sync facility is used to automatically synchronize their configurations.
The mate link service is also used for the synchronization of Guaranteed messages and message state between the primary and backup messaging nodes.
Failover Mechanism
The software event broker supports host list failover mechanism through which client connections are transferred from one message routing node to another upon the node failure. This mechanism uses lists of IP addresses, or corresponding DNS names, of both the primary and backup messaging nodes. The primary and backup messaging nodes have different IP addresses at all time, but only one of them is active and accepts connections. Connecting clients know these IP addresses, and the clients (not event brokers of the HA group) handle reconnecting from one IP address to the other.
The client API is responsible for connecting to whichever event broker is active in the HA redundancy group. This kind of configuration would be common in cloud environments.
Your client APIs and VPN bridge connections must be configured with the host lists for the primary and backup messaging nodes in the HA redundancy group. Once configured, if the primary messaging node becomes unavailable for any reason, the backup messaging node will take over activity, and the client APIs and Message VPN bridges will reconnect to the newly active event broker without impacting the client applications.
Client Host Lists
This failover mechanism relies on client applications using configured host lists to connect and reconnect to valid hosts for the HA redundancy group. For information about hostlists when using the Solace Messaging API, see Host.
When using host lists, the active software event broker will accept client connections on its static IP address, and the standby event broker will reject such connection requests. Primary and backup messaging node IP interfaces are ignored, and client connections to these interfaces are rejected too.
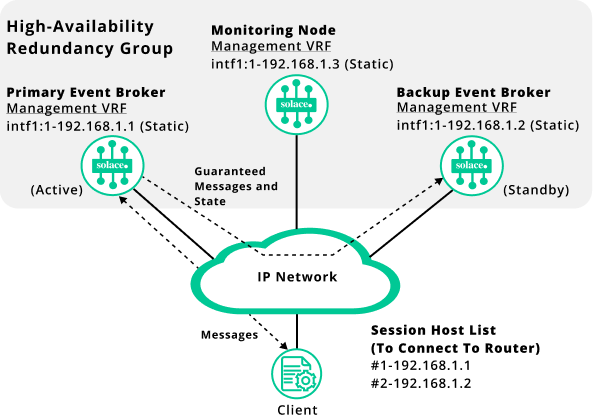
The client event brokers are connected to the primary messaging node in the redundancy group. The backup messaging node acts as the standby. Messages are passed from the primary messaging node to the client. Guaranteed messages and the message state between the event brokers get sent to the backup messaging node.
The client application’s host list is configured with two IP addresses:
- the primary messaging node’s static IP address (intf1:1-192.168.1.1) or the corresponding DNS name.
- the backup messaging node’s static IP address (intf1:1-192.168.1.2) or the corresponding DNS name.
VPN Bridging & Fault Tolerance
For details on how to establish Message VPN bridge connections to remote event brokers when those remote event brokers have been deployed in high-availability (HA) redundant event broker pairs for fault tolerance, refer to Bridging to Remote Event Brokers That Use Redundancy.
Software Event Broker IP Addressing
Software event brokers rely on a message backbone service for all messaging traffic to and from clients, and on a management service for management traffic. Both message backbone and management services share a single network interface. This is different from appliance event brokers that have two separate network interfaces.
By default the software event broker network interface is configured as a DHCP client. However, to use software event broker redundancy, each event broker instance in the HA redundancy group, including the monitoring node, must have a unique static IP address and this IP address must be in the same subnet and statically configured (that is, DHCP is not supported). Using static IP addresses in the HA redundancy group is a prerequisite for the software event broker redundancy functionality.
Failure Detection
All three nodes in the HA redundancy group—primary, backup, and monitoring—continuously communicate with each other using a protocol that runs over the static IP interfaces and by default, uses ports 8300, 8301, and 8302.
If the active event broker in the group becomes unreachable for any reason, and neither the monitoring node nor the backup messaging node can see the active event broker, but they can still see each other, then the backup messaging node will take activity, and provide messaging services to the clients.
Similarly, if the active event broker loses connectivity with both the standby event broker and monitoring node, the active event broker will give up activity, to eliminate the possibility it might be operating in a split-brain fashion. This implies that for an event broker to take (or keep) activity and provide service, it must be able to communicate with at least one other node in the group—either the mate event broker and/or the monitoring node.
For redundancy to function properly, all three nodes in the group need to be configured with static IP addresses of the other nodes in the group and the assigned role of each of the nodes (message-routing-node, or monitoring-node).
All three nodes in the HA redundancy group also need to be configured with the same HA redundancy group password as a security mechanism to ensure that only the nodes in the group can communicate with each other, and that other hosts on the network cannot impersonate the event brokers or attempt to join the HA redundancy group.
The following diagram shows a correct failure detection configuration.
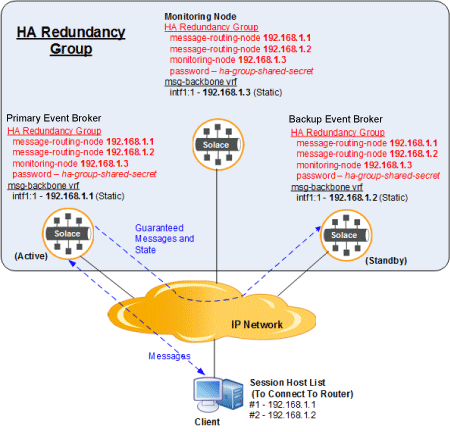
All three nodes in the HA redundancy group are configured with static IP addresses and have a shared password. The client event brokers are connected to the primary messaging node in the redundancy group. The backup messaging node acts as the standby. Messages are passed from the primary messaging node to the client. Guaranteed messages and the message state between the event brokers get sent to the backup messaging node.
Failover Sequence
If the active event broker goes offline, a failure is detected within a HA redundancy group.
Subsequently, a failover occurs in the following sequence:
- The backup event broker takes over messaging activity.
- Once the failed primary event broker comes back on-line, it resynchronizes to match the currently active backup event broker.
- The primary messaging node takes on the “Standby” role.
The following diagrams show a failover sequence in detail:
Normal Operation
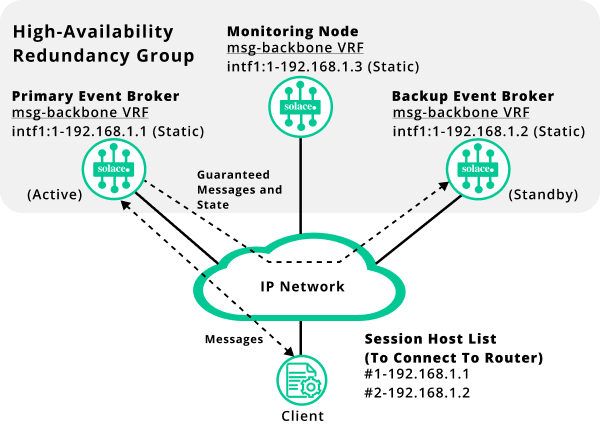
The following diagram shows a typical HA redundancy group under normal operation, when both the primary and backup messaging nodes are online and capable of providing service to the clients. This group is configured with the host lists for client connections (192.168.1.1 and 192.168.1.2). The client event brokers are connected to the primary messaging node in the redundancy group. The backup messaging node acts as the standby. Messages are passed from the primary messaging node to the client. Guaranteed messages and the message state between the event brokers get sent to the backup messaging node.
Taking Over Activity
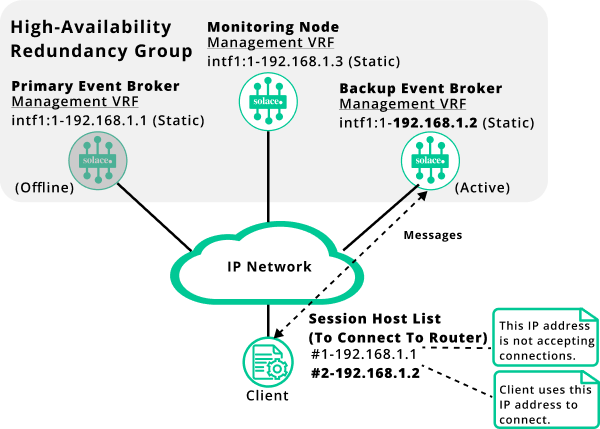
If the active event broker fails or is taken offline, the backup messaging node and monitoring node will detect the failure, and the backup messaging node will take over activity. When the backup messaging node takes activity, it will start accepting connections.
The diagram below shows the failover mechanism. Notice how the client uses the backup messaging node IP address 192.168.1.2 after the backup messaging node took over messaging activity.
Resynchronization
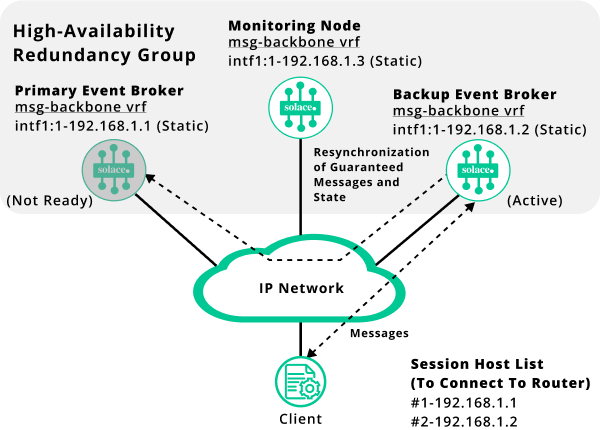
Once the failed event broker comes back on-line, it will use the mate link to resynchronize its message-spool contents to match the active event broker. This process may take a few seconds if the differences in the message-spool contents are minimal between the two event brokers, but it may also take several hours if the failed event broker was offline for a long time, and large quantities of data have been spooled on the active event broker.
Resynchronization is not a service-affecting operation, and the backup messaging node continues to service connected clients while the resynchronization is taking place. However, the primary messaging node is not able to provide service to clients during the resynchronization process. (Note that when disk resynchronization occurs, the redundancy status will be displayed as down.)
The following diagram shows the resynchronization process.
Taking on the Standby Role
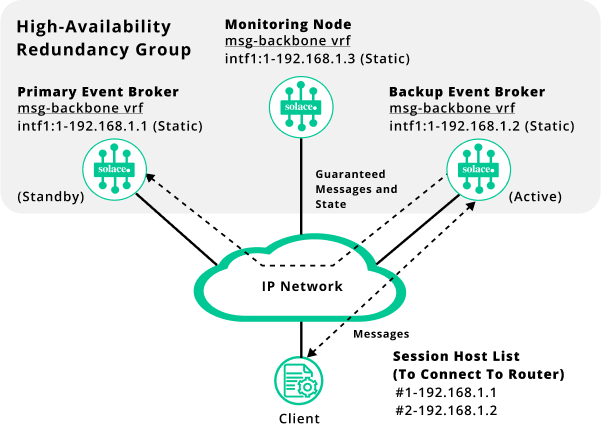
Once resynchronization has completed, the primary messaging node takes on the Standby role, and is available to provide service to clients should the backup messaging node go offline for any reason.
The following diagram shows this state of the HA redundancy group.
Next Steps
- HA Group Configuration shows you how to set up and use redundancy.