Best Practices for Designing an Event Mesh with DMR
This section explores some examples that show how to design an event mesh using Dynamic Message Routing (DMR). It also discusses Solace's recommendations for configuring certain aspects of your event mesh. Before you read these best practices, ensure that you also understand the event mesh core concepts described in DMR Terminology. In addition, you should also understand how subscription propagation works. This is discussed in detail in DMR Subscription Propagation and Data Forwarding.
Using DMR to Build an Event Mesh
In the example below we are going to look at a complex problem of building an event mesh for a large global organization. This example may not be reflective of your organization. This doesn't mean that you don't need an event mesh, just that your event mesh might be much simpler to visualize, and you might not require much help getting started.
The process of building an event mesh can be broken down to five steps:
- Design your topic hierarchy and begin a catalog of available events.
- Define your clusters.
- Connect your clusters into a mesh. This step defines the interactions between the clusters and their underlying applications.
- Consider how you want your clusters to grow.
- Manage data access for applications outside the event mesh.
Design the Topic Hierarchy
The main advantage of an event mesh is unlocking your data from silo-ed systems making that data easy to use. To achieve this, you must define a topic hierarchy that allows publishers to properly describe the data they are creating without conflicts. Proper topics also allow administrative control of data. Along with a topic hierarchy that conforms with the Topic Architecture Best Practices, you also need a catalog of available data as described by the topics. This catalog allows consumers to subscribe to the data they would like to consume. For an easy way to catalog and visualize event-related data, take a look at the Solace Event Portal Catalog.
Define the Clusters
The first step to building an event mesh is to define what constitutes a cluster. The goal should be to create homogeneous clusters, and there are a number of ways to do this, but a first approach would be to consider the sites and lines of business (LoBs) of your organization.
Step 1:
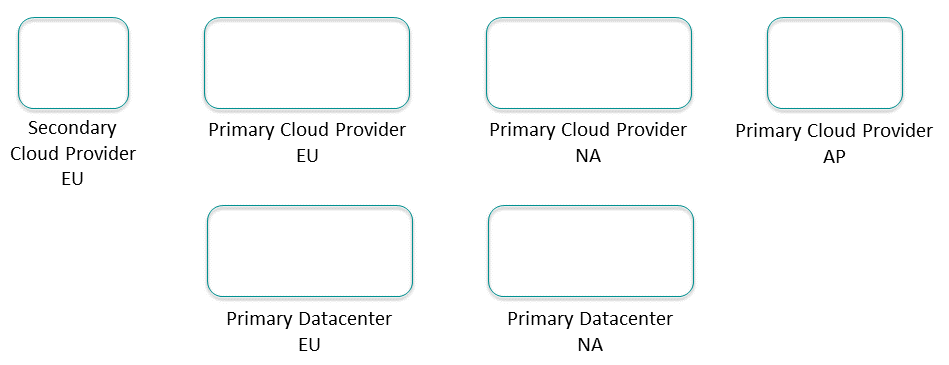
List all the data centers or cloud provider regions where applications run or will run. These will be the sites.
For example, in the diagram below, there are primarily Europe (EU) and North America (NA) Data Centers. Then also there is regional presence in primary and possible secondary cloud providers.
Step 2:
List all the foundational application domains— usually the lines of business (LoBs)—within your organization. Keep this at a high level, not a specific application or application team, but along the lines of product groups or cost centers within your organization. For a product manufacturing company these lines of business might be: Manufacturing, Inventory, Shipping, Sales, Finance, and Human Resources. Place the lines of business into the regions where their applications run.

At this point you have a view of the number of core clusters in your event mesh by adding up all the LoBs in each site; in this case there are 10 clusters in Europe, nine clusters in North America, and two clusters in Asia.
Connect Clusters into an Event Mesh
Now that you know what your DMR clusters look like, you must decide how they should connect to each other.
Step 1:
Assuming this isn't a completely greenfield situation, there is likely physical infrastructure that should be considered, such as cloud-to-data-center connections with VPN tunnels and firewalls. Try to overlay the event mesh as much as possible onto the existing infrastructure:
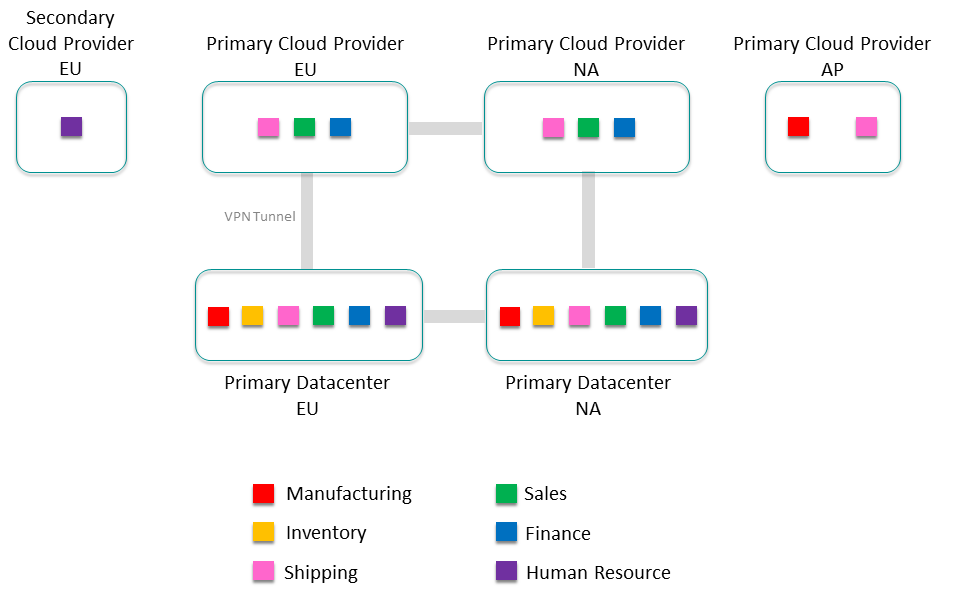
Step 2:
Now add external links between all the clusters that need to exchange data. It's expected that not all clusters will exchange data with every other cluster to start. You can construct the initial event mesh with just the known data exchange. It's even possible that some clusters don't exchange data with any other cluster. As all the event mesh data becomes cataloged and available, it's inevitable that the number of external links will grow. Plan to evolve the event mesh as your organization grows.
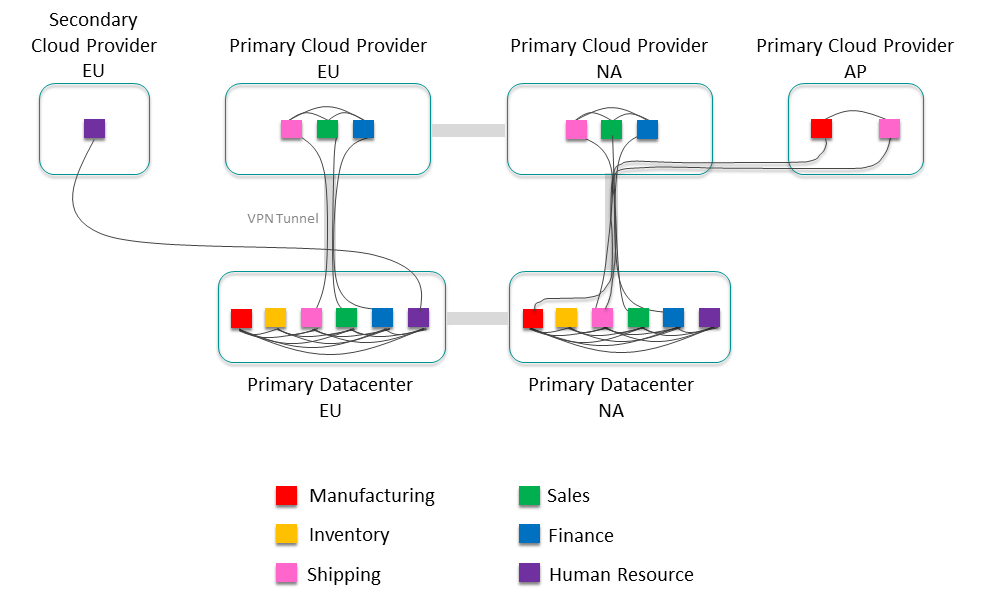
Consider Cluster Growth
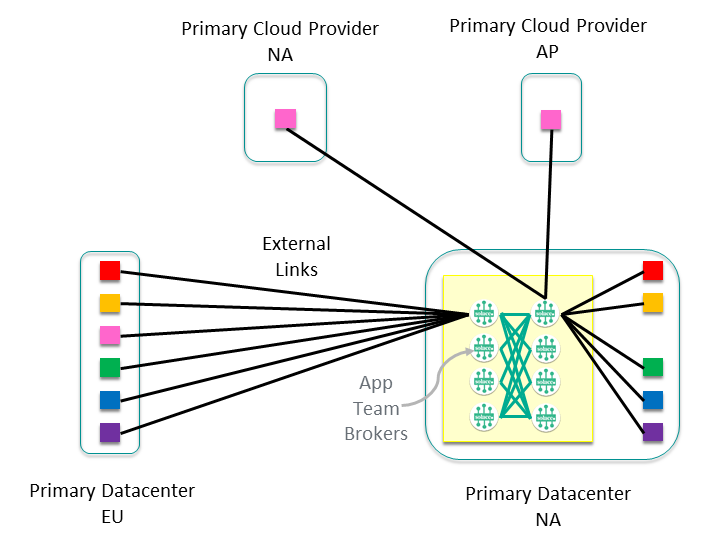
Now that the event mesh is laid out, let's look inside a cluster and to determine how best to design it with growth in mind. For example, the Sales cluster in the North America Primary data center would look something like this:
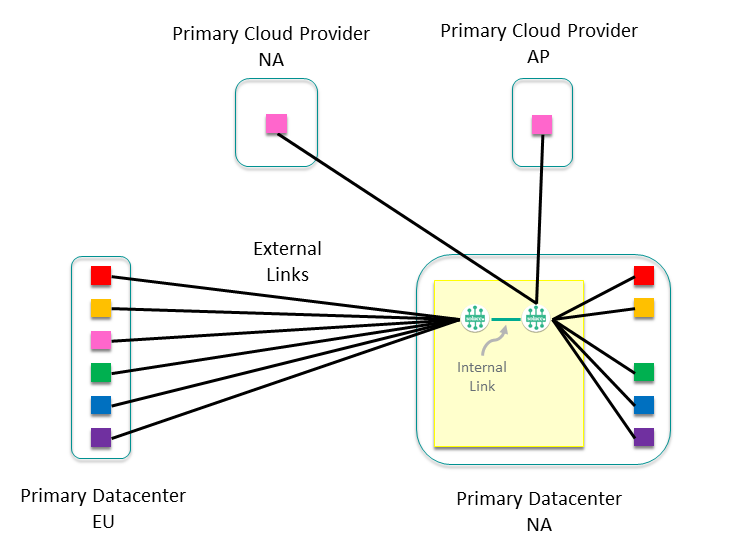
You can see external links to all the other clusters that it communicates with, as well as two internal nodes with the external links balanced across them. Depending on the number of external links and the expected growth of the cluster, you would normally have only one or two nodes to start with. From here, think about how you want the cluster to grow—a common approach is to give each application team or sub-domain their own node. This sub-divides the data exchanges and allows the intra-subdomain traffic to remain on a single event broker, allowing optimization of network usage, and making it easier to monitor traffic between application domains and sub-domains. This approach allows our cluster to grow to eight nodes dedicated to servicing Sales events within the North America data center.
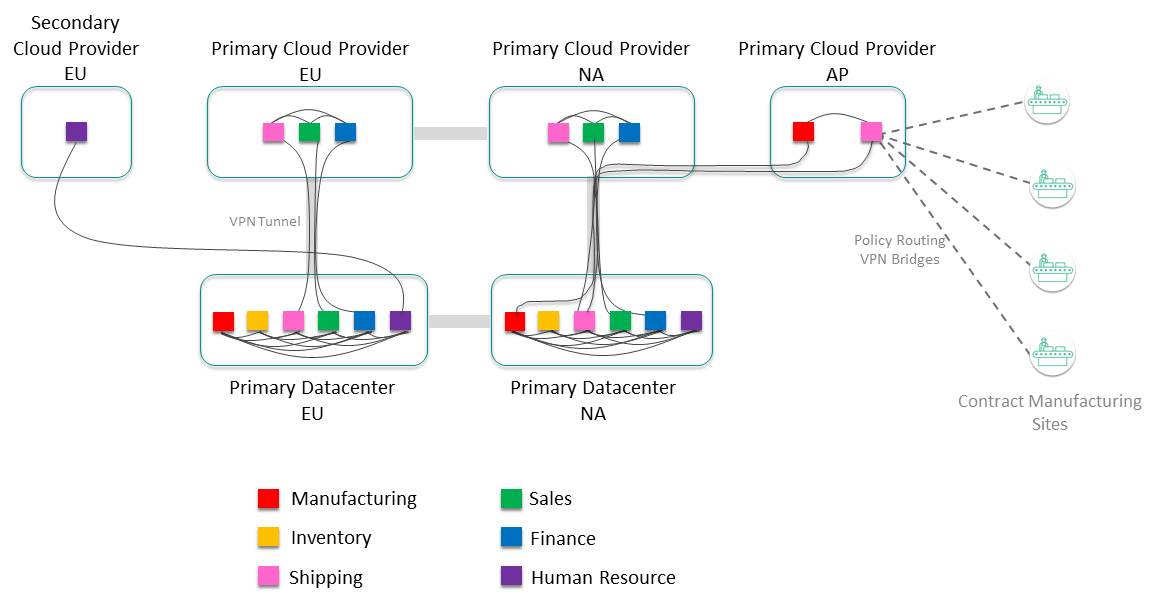
Manage Data Access for Applications Outside the Event Mesh
Finally, consider other sites that require additional control, for example contract manufacturing sites. The information from these sites might be very important, but you don't want to allow full access to the event mesh. You can use static VPN bridges with administratively-assigned subscriptions to allow access to certain data for these sites, while still controlling interface to the event mesh.
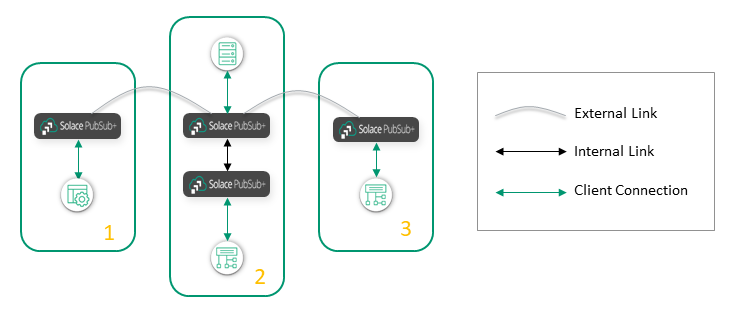
Expand Clusters or Connect Clusters?
How do you decide when to use internal links to grow your existing clusters, and when to use external links to join clusters together?
For example, suppose you have three clusters (Cluster 1, Cluster 2, and Cluster 3), with external links between Cluster 1 / Cluster 2, and between Cluster 2 / Cluster 3. This means that Cluster 1 can exchange events with Cluster 2, and Cluster 2 can exchange events with Cluster 3, but Cluster 1 cannot exchange events with Cluster 3.
What is the best way to connect the nodes in Cluster 1 and Cluster 3? You can add an external link between Cluster 1 and Cluster 3:
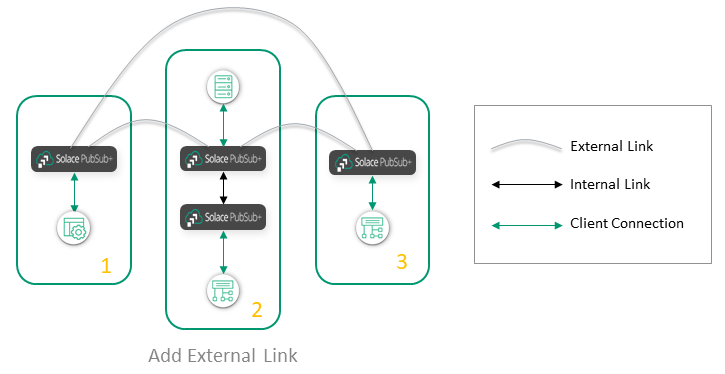
Or you can "stretch" Cluster 2 to include the nodes in Cluster 3:
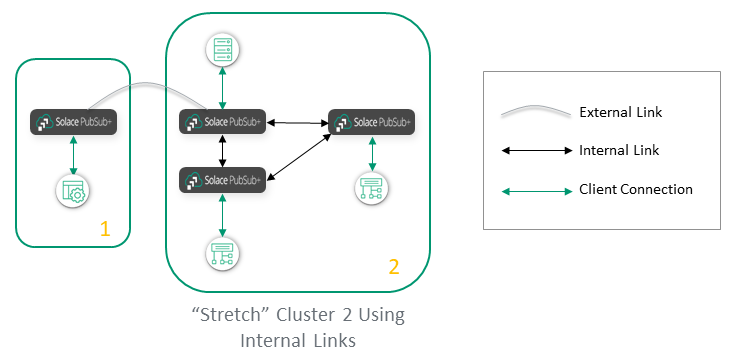
A general recommendation is to use internal links within a site, like a data center or a public cloud region, and use external links between sites. However, there are a few factors that would influence how this general rule is interpreted.
Specifically, use an external link when:
- There is low bandwidth and/or high cost and latency between sites (e.g., inter-continental links, links to remote locations). External links are best in this scenario, because if a message has to be fanned out to several brokers on the remote site, it's better to send it only once to the remote site over an external link, than to send it many times over internal links (once for each broker in the remote site).
- There is a financial cost to having the message leave a domain or site. For example, if you are linking brokers between cloud providers, each cloud provider often charges for any data leaving its cloud. So, you want to only have the data leave once, over an external link, rather than once for each broker in the other cloud provider.
- You want to build a hub-and-spoke topology, where brokers on the spokes never exchange messages with brokers on other spokes. External links are the way to connect the spoke clusters to the hub cluster.
However, if there is good, low-cost connectivity within a region, then there is no good reason not to group all the sites in the region into one big cluster (other than the limit on the number of nodes). It's the simplest approach, and it assures the best connectivity, avoiding the risk of gateway brokers being a bottleneck.
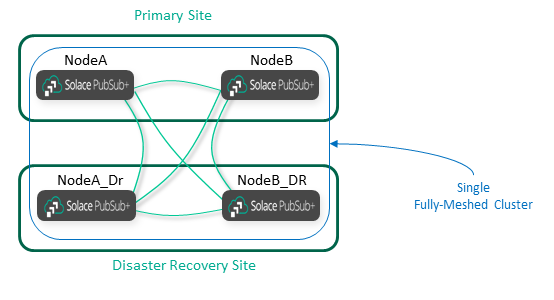
How Disaster Recovery Affects the Event Mesh
As described here, disaster recovery (DR) works on a node-by-node basis. You must have a replicated node for each node you want to protect with DR. The replicated node must be in the same cluster as the primary node, and it must have a full mesh of internal links as per normal rules. In most cases the cluster should be stretched to include the primary site and the DR site.
When you add external DMR links or VPN bridges, you must connect them to both the primary and DR sites, as shown in the following diagram:
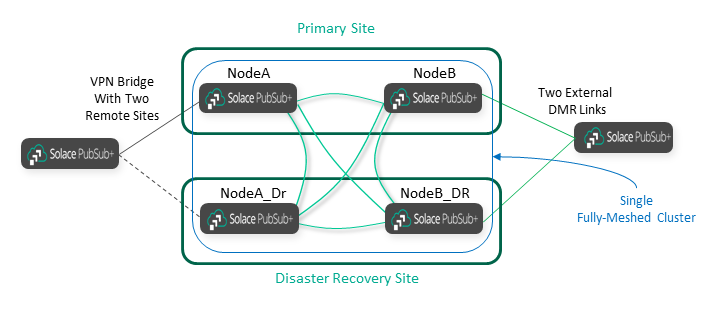
As you can see, adding Disaster Recovery affects the DMR architecture in three ways:
- DR doubles the number of internal DMR links inside the cluster that is being protected.
- DR requires stretch clusters across the Primary and DR sites.
- DR doubles the links that external clusters must have, because they must connect to both sites.
Securing the Event Mesh
The main goals for securing your event mesh are to allow only authorized people to view the data, and to prevent unauthorized people from viewing or manipulating the data. Since DMR links transit between the confines of secure data centers, they might be more vulnerable and selected for attack.
The straightforward solution to this problem is encrypting the data with TLS, along with using authentication (username and password or mutual authentication certificates). Digging deeper, the best solution is layers of defense.
Between sites, we recommend using secure VPN tunnels with firewalls terminating either end. We recommend that you do not expose your event brokers directly on the public Internet. Also, it's best to terminate the VPN onto a subnet of specially-purposed termination devices such as event brokers, and use this as a DMZ, and then abstract the data processing and data storage applications into another subnet that doesn't have any Internet access.
Establishing connections from the most secure general location, such as a data center, to a site like a DMZ subnet is generally preferred. Do not open data center firewall rules to allow connections.
All of these principles are show in the diagram below. In this example, the data center event brokers connect to the cloud event brokers via secure VPN tunnels. Inter-cloud connection should be done via cloud-provided mechanisms. Applications should be in private subnets that are not exposed to the public Internet or even to the VPN tunnels.
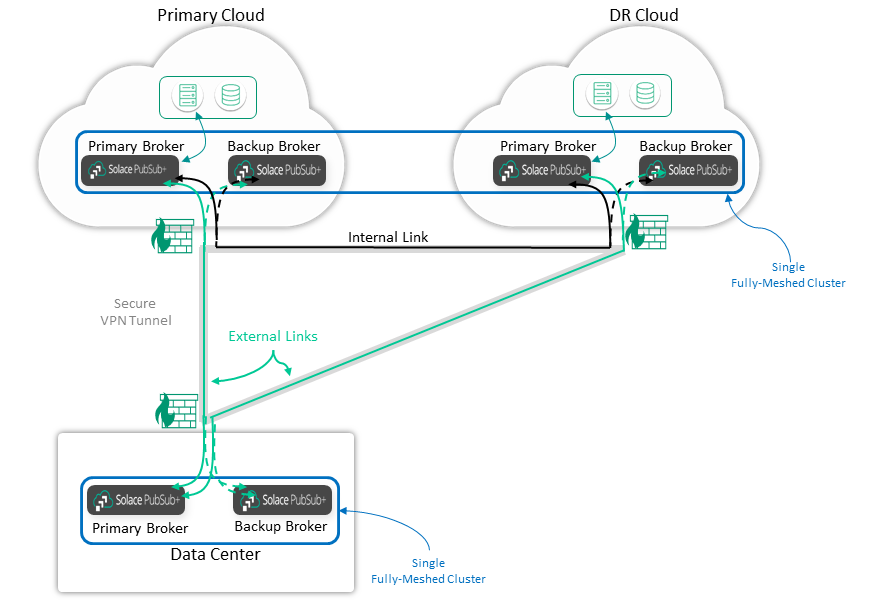
Finally, there are several connections for HA and DR, which can be a challenge for certificate management if TLS is used. We recommend that the Primary and Backup event brokers use the same server certificate, with the CN or Subject Alt Name (SAN) covering both devices. Do not try to swing the DNS name of the Primary site to the DR site but instead use host lists for these different sites. That is, the Primary/Backup event brokers in the Primary and DR sites may have different server certificates, and the certificate SAN doesn't necessarily have to cover all sites. It's better if the DR site has a different DNS name and certificate in case the Primary site's certificate becomes compromised.
Getting Help
Building an event mesh can quickly become a complex architectural exercise. If you're building a mesh with more than a couple of clusters, or you have specific networking or security constraints, we recommend you contact Solace for assistance.