Queues
A queue acts as both a destination for published Guaranteed messages and as an endpoint that clients can bind consumers to and consume messages from. A queue is typically used in both point-to-point (PTP) messaging environments and in a publish and subscribe (pub/sub) model.
Queues are significantly more flexible than Topic Endpoints and are the recommended approach for most applications.
If you are familiar with Java Message Service (JMS):
- A Durable queue is equivalent to a JMS durable subscription.
- A Temporary queue is equivalent to a JMS non-durable subscription.
For more information about JMS, see JMS to Solace Terminology Mapping.
Queue Access Types
A queue has an access type, which determines how messages are delivered when multiple consumer flows are bound to it. Queues can be assigned one of the following access types:
-
exclusive—specifies that only one consumer can be active on the queue. If other consumers attempt to bind and themax-bind-countvalue of the queue is not exceeded, they will bind, but remain inactive until the active consumer is unbound and a new active consumer is chosen from the queue's inactive consumers. An exclusive queue always delivers messages in the order they are received. -
non-exclusive—specifies that multiple consumers can bind to the queue, which enables load balancing and consumer auto-scaling. A non-exclusive queue can be non-partitioned or partitioned.- For a non-partitioned queue (partition count is zero), each consumer is serviced in a round-robin fashion. If a connection fails, unacknowledged messages are delivered to another consumer with the re-delivered flag set. In this way, messages can be delivered to consumers out of order. This type of queue is sometimes referred to as a "competing consumer" queue.
- For a partitioned queue (partition count is greater than zero), each consumer is delivered messages from one or more partitions. Messages are mapped to partitions based on a hash of the partition key, which is set by the publishing application. Message order is maintained within a partition, but not between partitions.
The access type can be changed for a durable queue, but only when consumer access to the queue (that is, message egress) has been disabled.
We recommend disabling ingress and allowing messages to drain from the queue before changing a non-exclusive queue from partitioned to non-partitioned or vice versa:
- If a queue changes from partitioned to non-partitioned or vice versa, the event broker unbinds all clients already bound to the queue. This ensures that the event broker and clients are consistently using (or not using) the semantics for partitioned queues. Note that any messages remaining in deleted partitions are also deleted.
- If a queue changes from non-partitioned to partitioned, messages that are enqueued at the time of the change may get stuck because the broker no longer delivers messages from the parent queue after the queue becomes partitioned. In this case, messages can be copied out of the parent queue.
Queue browsing is supported for exclusive queues and non-exclusive, non-partitioned queues.
For information about creating queues, configuring access types, and disabling message egress using the Solace Event Broker CLI, see Configuring Queues Using the Solace Event Broker CLI.
For information about creating and configuring queues in Broker Manager, see Configuring Queues for Solace Cloud or Configuring Queues for software event brokers and appliance event brokers.
You can also configure queues in Solace Event Portal and push the updates to an event broker if runtime configuration is enabled. For more information, see Configuring Event Brokers in Event Portal.
For more information about collecting queue data, see Viewing Endpoint Messaging Data for Solace Cloud or Viewing Endpoint Messaging Data for software event brokers and appliance event brokers.
Summary of Queue Access Types
| Queue Property | Exclusive Access Type | Non-Exclusive Access Type | |
|---|---|---|---|
| Non-Partitioned | Partitioned | ||
| Message Distribution | Single consumer | Multiple consumers with round-robin message delivery. | Dynamic consumer support. The number of active consumers is limited to the number of provisioned partitions. |
| Message Order | Guaranteed | Not guaranteed | Guaranteed within each partition, but not between partitions. |
| Queue Browsing | Supported | Supported | Not supported |
Well-Known Queues
Any queue, durable or non-durable, with a commonly recognized name is a well-known queue. The well-known queue name is specified by the application rather than being generated by the API. Applications can send messages to a well-known queue without any communication with the creator of the queue. A well-known queue name can be used to send messages to the queue, as long as it exists somewhere within a network of event brokers.
One of the key features of the well-known queue is its durability. Administrators can use queue templates to control the durability of well-known queues. A well-known durable queue can be converted to a well-known non-durable queue by specifying durability override through a queue template.
When using a well-known non-durable queue in a request/reply messaging pattern, there is a race condition where the recipient of a request might reply before the respondent's node knows how to route the response to the requestor's node. As such, well-known queues are not recommended for use in a request/reply messaging pattern. For the request/reply pattern, it is recommended to use the client's #P2P topic prefix for a direct messaging reply-to and an anonymous queue's network topic as a reply-to for guaranteed messaging.
Well-known queues can be created by management interfaces such as the Solace Event Broker CLI, Broker Manager, and SEMPv2, or they can be created by applications through the Solace Messaging APIs.
Anonymous Queues
Unlike well-known queues, the anonymous queue name is generated by the API rather than being specified by the application, hence the queue name is not well known. To send a message to an anonymous queue, the destination must be sent to peers as it is not known ahead of time. Often this is done in the reply-to field of a message in a request/reply messaging pattern. A mechanism is built into event brokers to prevent race conditions in sending to anonymous queues after they are created. This makes anonymous queues particularly well-suited for request/reply messaging patterns.
Anonymous queues are always non-durable, which means the queue and the data on the queue are removed when a client unbinds from the queue or the client is disconnected and fails to re-establish session within sixty seconds.
Dead Message Queues
Guaranteed messages are removed from a durable endpoint's message spool in the following circumstances:
-
A message TTL value has been exceeded and the endpoint is configured to respect message TTL expiry times.
-
Message delivery to the client fails and the number of redelivery attempts for the message exceeds the Max Redelivery value for the original destination endpoint.
-
Message delivery was rejected by the consuming client.
The default behavior for messages that are removed from a durable endpoint's message spool depends on the version deployed on your event broker:
-
In version 10.25.9 and earlier, messages removed from the queue are deleted. However, messages flagged as dead message queue (DMQ)-eligible by the publishing client can instead be sent to a DMQ assigned to the endpoint.
-
In version 10.25.10 and later, all messages removed from the queue are sent to the DMQ assigned to the endpoint. However, you can instead configure the event broker to respect the DMQ-eligible flag set by the publisher, effectively preserving the behavior from earlier versions.
When a message is moved to a DMQ because it could not be delivered to the client application, you can copy it back to the original queue if you have resolved the client issue and want the message to be delivered. The message returned to the queue is eligible to be sent back to the DMQ again if it still can't be delivered. For more information, see Copying a Message From One Endpoint to Another.
When a message with a non-zero TTL expires and moves to the DMQ, the original TTL value no longer applies to that message in the DMQ. However, if the DMQ itself has a configured maximum TTL value, this setting causes expired messages to be deleted from the DMQ once they reach that maximum time limit. You cannot chain DMQs together. In other words, if a message moved to the DMQ with a configured TTL expires, it cannot be sent to another DMQ.
Any durable queue on the same Message VPN as the endpoint that the messages were spooled to can be assigned as that endpoint's DMQ. Although durable endpoints are assigned a default DMQ (#DEAD_MSG_QUEUE), every durable endpoint can be assigned a specific DMQ and a Message VPN can have multiple DMQs.
If an endpoint's assigned DMQ does not exist, the messages are discarded even if they are DMQ-eligible. A management user must manually create and name DMQs, including the default #DEAD_MSG_QUEUE.
In version 10.25.16 and later, when creating endpoints in Broker Manager, the DMQ Name field defaults to blank. This means that if you create a queue named #DEAD_MSG_QUEUE, new endpoints do not automatically use it as a DMQ. You must explicitly configure the DMQ Name field for each endpoint to enable dead message processing.
When messages are delivered to an endpoint through topic-to-queue mapping, and that message is subsequently moved to the default DMQ used by multiple endpoints, there is no way for an application servicing the DMQ to know which endpoint the message came from. Solace recommends that you use a separate DMQ for each queue and topic endpoint that needs one. Separate DMQs make it easier to manage dead messages from multiple queues and makes investigating DMQ messages easier.
A partitioned queue can have or be a DMQ.
For information about configuring DMQs using the Solace Event Broker CLI, see Configuring Dead Message Queues Using the Solace Event Broker CLI.
For more information about configuring DMQs in Broker Manager, see Configuring Dead Message Queues for Solace Cloud or Configuring Dead Message Queues for software event brokers and appliance event brokers.
DMQ Feature Interactions
Using High Availability
Solace event brokers in a high availability (HA) group should have their clocks synchronized with a Network Time Protocol (NTP) serverntp-server CONFIG command.
Using Replication
If you're using replication, and ACK propagation is enabled for the endpoint (enabled is the default value), replicated messages on the standby site that exceed their TTLs will be discarded rather than moved to a DMQ. If you disable ACK propagation, then the TTL timers will run independently at both sites and lead to differences between the messages spooled at each site. Solace recommends that you don't disable ACK propagation.
Last Value Queues
If a queue is assigned a maximum spool size of 0, the queue spools only the last message it received, regardless of the message priority value. For a partitioned queue, each partition holds the last message spooled to the partition. In this configuration, the queue acts as a so-called last value queue.
Like other queues, the message is removed from the queue if the queue receives an acknowledgment (ACK) that the message was consumed.
You can set a queue as a last value queue in these ways:
-
Set the
max-spool-usagevalue for the queue to0using the Solace Event Broker CLI, For more information, see Configuring Queues Using the Solace Event Broker CLI. -
Set the Messages Queued Quota for the queue to
0in Broker Manager. For more information, see Configuring Queues for Solace Cloud or Configuring Queues for software event brokers and appliance event brokers.
Application of Topic Subscriptions
A client publishing Guaranteed messages can apply a topic subscription to a last value queue so that it attracts all the messages that the client publishes. This allows the client to use the last value queue to accurately determine the very last Guaranteed message that it successfully published.
This could be beneficial, for example, if an application failure occurs after a message has been published. In this case, if the client application does not receive an acknowledgment from the event broker for the message, it does not know if the published message was lost entirely, or if the message was received but just the acknowledgment was lost. If a last value queue is used, when the client reconnects and rebinds to the last value queue, it can determine what was the last successfully published message, and it can continue publishing from where it left off without creating duplicate messages or losing messages.
When there is more than one publisher for a given topic, the publisher should be identified in the published topic, which can be wildcarded by subscribing applications.
For example, assign the last value queue for each publishing client a topic subscription of the form uniquePubId/> (with Pub1/> for the first publisher, Pub2/> for the second publisher, and so on). The clients can then publish messages to topics of the form uniquePubId/some/hierarchical/topic/. For example, Pub1 might publish to Pub1/price/equities/apple, while Pub2 might publish to Pub2/price/equities/apple, and so on. This allows clients to specifically subscribe to their own last value queue, but other clients, who also want to receive messages on those topics, can use a topic subscription of the form */some/hierarchical/topic. For example, */price/equities/apple.
Message Selectors
Message selectors are not supported with last value queues.
Queue Browsing
Client applications using Solace Messaging APIs can create a queue browser in a session to look at messages spooled on a queue in order of oldest to newest without consuming them. That is, browsing messages returns the full content of messages, complete with all message headers and payloads, but those browsed messages are not removed from the message spool. You should be aware that when you browse a queue that has an active consumer, it's possible that the browser won't receive all messages published to the queue because the consumer can receive and acknowledge messages before they are delivered to the browser.
The figure below shows how a Browser Flow returns messages from the queue, without consuming them so that clients with established Flows can still consume them. In this example, a selector string is also used so that the client application only browses messages that match that selector. For more information, see Selectors .
Queue Browsing
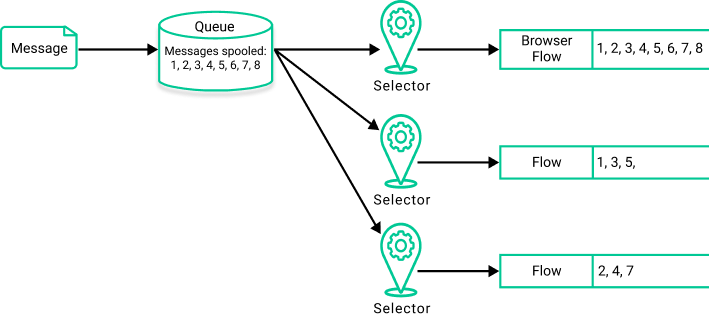
Queue browsing is not supported for Partitioned Queues.
Partitioned Queues
A partitioned queue consists of a parent non-exclusive queue, along with a child queue for each partition. For example, a partitioned queue with four partitions consists of a single non-exclusive parent queue and four additional child queues.
The parent queue holds the configuration state of the partitioned queue, including the subscription set and the combined message quota of the partitions. The parent queue does not retain messages and does not consume any quota. The partitions (child queues) are completely hidden from publishing and consuming applications. Partitions are neither directly accessible nor directly configurable.
A partitioned queue object has a partition count property that specifies the number of partitions it has. Partitions are numbered from 0 to N-1, where N is the number of partitions.
For information about configuring partitioned queues using the Solace Event Broker CLI, see Configuring Partitioned Queues.
For more information about configuring partitioned queues in Broker Manager, see Configuring Partitioned Queues for Solace Cloud or Configuring Partitioned Queues for software event brokers and appliance event brokers.
Publishing to and Consuming from Partitioned Queues
The event broker distributes messages among the partitions in a partitioned queue based on a key (the partition key) carried in the messages. Publishing applications set this key when they create a message. The event broker creates a hash of the partition key and selects the destination partition for a particular set of messages using the following calculation:
partition = partition-key-hash MOD partition-count
This relationship between the partition key and its destination partition is referred to as the key-to-partition mapping. All messages with the same key are handled by the same partition. If no partition key is set, the event broker generates a random hash value, which causes the message to be spooled to a random partition.
Consuming applications bind to a partitioned queue and consume messages the same as with any other queue. The event broker maps one or more partitions to each consumer flow. This is called the partition-to-flow mapping.
Message sequence is maintained within a partition, but not between partitions.
For details about how the broker handles messages in partitioned queues, see Message Distribution with Partitioned Queues
Adding and Removing Partitions
Partition scaling refers to adding or removing partitions. You add or remove partitions by changing the partition count of the queue.
To avoid message loss, we recommend that you ensure messages are drained from the queue before making any of these administrative changes. For more details and specific instructions for adding and removing partitions, see Partition Scaling.
Partition scaling is service affecting. Ensure that you follow the exact procedures provided in Partition Scaling to add or remove partitions.
Changing the Number of Consumers
When the number of consumers (that is, bound flows) of a partitioned queue changes, the partition rebalancing process is triggered. Rebalancing involves reassigning partition-to-flow mappings such that flows are distributed evenly across all partitions, with each partition assigned to a single flow (but note that a flow can be assigned more than one partition). See Partition Rebalancing for more information.
As part of rebalancing, the event broker often transfers partitions to different client flows. This process, called partition handoff, has implications for the design of consuming applications. For a detailed discussion about this process and how your application can respond to changes in partition-to-flow mappings, see Partition Handoff.
Partitioned Queue Feature Interactions
- Direct Message Delivery Mode
-
A direct message can have a partition key set, although this has no meaning to the broker unless that direct message is promoted into a partitioned queue. Otherwise the partition key is simply carried through the Broker from ingress to egress.
- High Availability (Redundancy)
-
The event broker's partition-to-flow mappings are maintained across HA failovers. From the perspective of client applications, there is no difference in redundancy behavior between partitioned and non-partitioned queues.
- Disaster Recovery (Replication)
-
Replication of messages destined for a partitioned queue is supported, with the following caveats:
-
If the proper procedure for partition scaling is not followed, messages replicated to the DR-standby may end up in a different partition than on the DR-active. This is due to the fact that configuration changes on the DR-active site are coordinated with the DR-standby site out of band with the delivery of data messages. For example, a change to the
partition counton the DR-active site is sent to the DR-standby site through config-sync, but the timing for acting on that change relative to data messages is uncoordinated. After partition scaling on both sides has completed, messages can be expected to wind up in the same partitions. -
If the proper procedure for partition scaling is not followed, ACK propagation from DR-active to DR-standby may fail because the acked message is in the wrong ancillary queue. Typically such messages are acked when subsequent messages are acked (due to our use of ranged ACKs) but, regardless, they will not be acked at the proper time.
-
If a failover occurs from the DR-active site to the DR-standby site, no coordination of previous relationships between partitions and consumer flows is maintained.
-
- REST Delivery Points
-
REST Delivery Points cannot bind to partitioned queues.
- Active Flow Indication
-
The Active Flow Indication is supported for partitioned queues. Although clients bind to the parent (non-exclusive queue), internally the flow is actually assigned to one or more of the child partitions. When a flow is assigned its first partition it is considered to have transitioned to "active". Flows that are assigned no partitions (for example, if there are more flows than partitions) are considered "inactive".
- Queue Browsing
-
Queue browsing is not supported for partitioned queues. The event broker rejects requests from a browsing flow to bind to a partitioned queue.
- Selectors
-
Selectors are not supported for partitioned queues. The event broker rejects a bind request to a partitioned queue if the request includes a selector.
- Transactions
-
Local transactions are supported for both publish and subscribe, with the caveat that the commit of a local publish transaction fails if the selected partition is deleted between the time the message is received and the time the transaction is committed (due to a configuration change in the interim). In this case, the transaction can simply be retried.
XA transactions are not supported for either publish or subscribe:
- Client-Signaled Behaviors
-
Client applications cannot create partitioned queues. Partitioned queues must be administratively provisioned.
Client applications can manage the subscriptions of partitioned queues.
- Replay
-
Message replay is not supported for partitioned queues.
- Deleting Messages from Partitioned Queues
-
To delete messages that are spooled in a child queue, you must specify the name of the child queue in the
delete-messagescommand. If you run thedelete-messagescommand on the parent queue (that is, without specifying a partition), the event broker deletes any messages that were spooled directly to the parent queue before it became partitioned. - Copying One Message to Endpoint
-
Messages can be stranded in the parent queue if that queue changes from non-partitioned to partitioned. In this case, messages can be copied out of the parent queue.
Messages can be copied to or from a partition.
- AMQP
-
AMQP publishers can set the
group-idattribute on their messages, and the event broker maps this property directly to the partition key property. This mechanism supports the publish-side behavior of partitioned queues. - MQTT
-
MQTT 3.1 publishers have no means to set the partition key for a message. Their messages can be delivered to partitioned queues but are assigned a random partition.
MQTT 5.0 publishers can set
JMSXGroupIDas a user property on their messages, and the event broker maps this property directly to the partition key property. This mechanism supports the publish-side behavior of partitioned queues.MQTT subscribers do not have the ability to bind to an arbitrary queue, and so have no means to draw messages from a partitioned queue.
- HTTP
-
Any HTTP publisher can provide a partition key by using an HTTP header option of
Solace-User-Property-JMSXGroupID. The event broker translates this field to the equivalent SMF header and triggers publish-side partitioned queue behavior. - Distributed Tracing
-
Partitioned queues are traced the same as non-partitioned queues.
- Dead Message Queue Handling
-
A partitioned queue can have a DMQ configured for it. Messages expire from all partitions of a partitioned queue into the single configured DMQ.
A DMQ may itself be a partitioned queue. Any expiring message is put into the partitioned DMQ based on the hash of the message's partition key, or into partition 0 if there is no hash.